信息抽取在知識圖譜構建中的實踐與應用 以信息系統集成服務為例
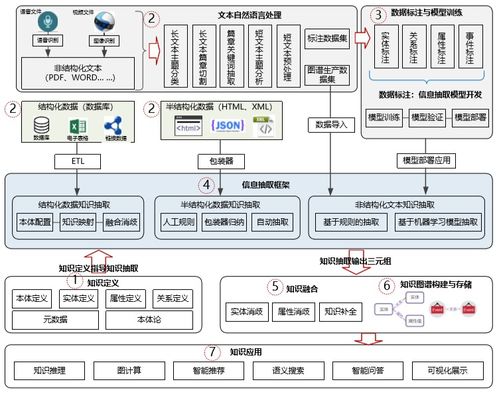
知識圖譜作為一種結構化的語義知識庫,已成為驅動智能搜索、精準推薦與深度分析的核心基礎設施。其構建過程涉及知識獲取、表示、融合與應用等多個環節,其中,知識獲取是基石。信息抽取技術,旨在從海量、異構、非結構化的數據源中自動識別并提取出實體、關系、屬性等結構化信息,是實現高效、自動化知識獲取的關鍵手段。本文將聚焦于信息系統集成服務這一特定領域,探討信息抽取技術在其知識圖譜構建中的具體實踐與應用價值。
一、 信息系統集成服務的知識圖譜需求
信息系統集成服務旨在將多個獨立的信息系統、應用、數據源和技術組件,通過標準化的接口、協議與平臺進行連接與整合,形成一個協同工作的統一整體。在這一領域構建知識圖譜,核心目標在于實現:
1. 技術資產與能力圖譜化:清晰刻畫各類硬件設備、軟件系統、中間件、API接口、數據格式、通信協議等“技術實體”及其間的依賴、調用、兼容等“技術關系”。
2. 解決方案與案例知識化:將成功的集成項目方案、解決的技術難題、適配的業務場景等經驗性知識,提煉為可檢索、可復用的知識單元。
3. 專家經驗與團隊能力顯性化:關聯技術專家、項目團隊與其擅長的技術領域、參與過的項目,形成“人-知識-項目”網絡。
此類圖譜能夠極大提升方案設計效率、降低集成風險、促進知識傳承與團隊協作。
二、 關鍵信息抽取技術的實踐應用
在信息系統集成服務領域,知識來源多樣,包括技術文檔、設計方案、項目報告、API手冊、系統日志、會議紀要等。針對這些數據,信息抽取技術主要應用于以下方面:
- 命名實體識別:這是基礎步驟。模型需要能夠準確識別文本中的技術專有名詞,如“Oracle數據庫”、“Kafka消息隊列”、“RESTful API”、“單點登錄(SSO)”、“微服務架構”等。這通常需要結合通用領域模型與在特定領域語料(如技術白皮書、產品文檔)上進行的增量訓練或微調。
- 關系抽取:識別實體間的語義關聯是構建圖譜連接的核心。例如,從“系統A通過HTTP API調用系統B的用戶服務接口”中,抽取出(系統A,調用,系統B的用戶服務接口)這樣的三元組。關系類型可能包括“依賴”、“調用”、“集成于”、“替代方案”、“版本迭代”等。實踐中,除了基于規則和傳統機器學習的方法,基于預訓練語言模型(如BERT、ERNIE)的序列標注或文本分類方法展現出更強的泛化能力。
- 屬性抽取:用于豐富實體節點的細節。例如,從一個API文檔中抽取某接口的“請求方法”(GET/POST)、“參數格式”(JSON/XML)、“響應時間”、“認證方式”等屬性。這常通過結合文本模板與信息槽填充技術來實現。
- 事件抽取:針對項目報告或案例,抽取關鍵的項目事件,如“系統遷移”、“數據同步”、“性能調優”、“故障排查”等,并關聯事件的主體、時間、結果及涉及的技術組件。這有助于構建動態的、基于事件的項目知識脈絡。
三、 實踐流程與挑戰應對
典型的實踐流程包括:數據采集與預處理、領域本體(Schema)定義、信息抽取模型選型與訓練(或規則編寫)、知識三元組生成、與已有知識庫的融合消歧、最終入庫形成圖譜。
在這一過程中,面臨的主要挑戰及應對策略包括:
- 領域術語的快速變化與歧義:技術領域新概念、新縮寫層出不窮(如“云原生”、“服務網格”),且同一術語在不同上下文含義不同(如“網關”可能指API網關或網絡網關)。解決方案是建立動態更新的領域詞典,并利用上下文感知的深度學習模型進行消歧。
- 非結構化文檔的復雜性:技術文檔常包含大量圖表、代碼片段、結構化表格與自由文本混合。需要采用多模態信息抽取或設計專門的預處理模塊,將圖表、表格內容轉化為可處理的文本信息。
- 知識融合與質量保證:從不同來源抽取的知識可能存在沖突、重復或表述不一致。需要建立實體鏈接和消歧機制,并設計人工審核與反饋閉環,持續迭代提升抽取準確率與圖譜質量。
四、 應用價值與未來展望
通過信息抽取技術構建的信息系統集成服務知識圖譜,其應用價值顯著:
- 智能方案輔助設計:工程師輸入需求,系統可自動推薦匹配的技術組件、架構模式及歷史類似案例。
- 集成影響分析:當某個系統或接口需要變更時,圖譜可快速可視化其依賴關系,評估影響范圍。
- 知識檢索與問答:提供比傳統關鍵詞搜索更精準、關聯性更強的技術知識查詢與智能問答服務。
- 團隊能力評估與項目匹配:基于“人-知識”網絡,為項目分配合適的技術專家。
隨著大語言模型技術的發展,其強大的零樣本/少樣本學習與上下文理解能力,有望進一步降低信息抽取對標注數據的依賴,提升對復雜、隱含關系抽取的準確性。與自動化運維、智能客服等場景的深度結合,將使基于信息抽取的知識圖譜真正成為驅動信息系統集成服務智能化升級的核心引擎。
如若轉載,請注明出處:http://www.apcq.cn/product/39.html
更新時間:2026-05-18 16:15:51